AOI Composer
July 4, 2026
Loading code snippet...I've been working a decent amount with AOI camera measurements and have been working on some ways to visualize and debug a manufacturing line given those measurements. I was using some minitab to do some statistics but it did not handle the amount of data quickly and formatting to be in the right shape for what minitab wanted was a bit of a chore. So I've been using a bit of python.
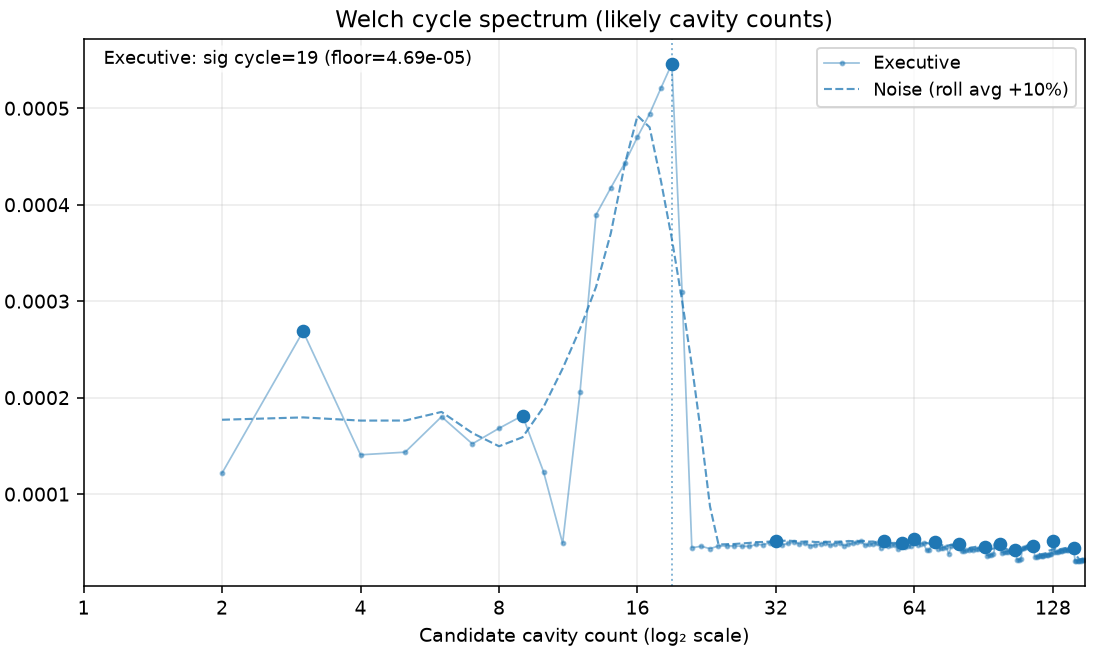
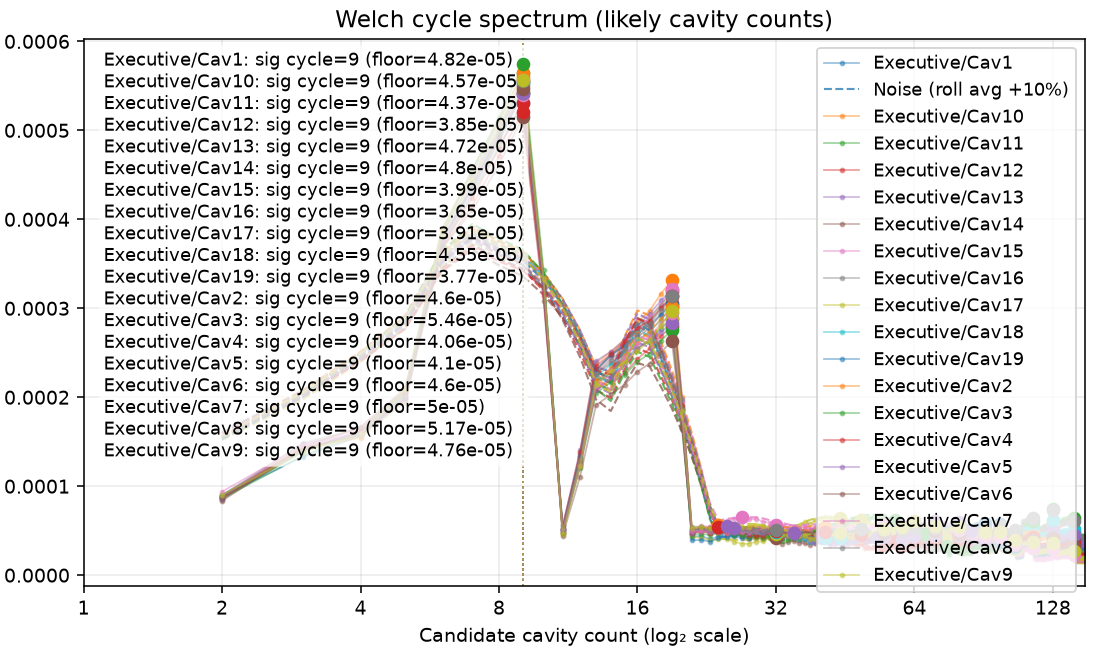
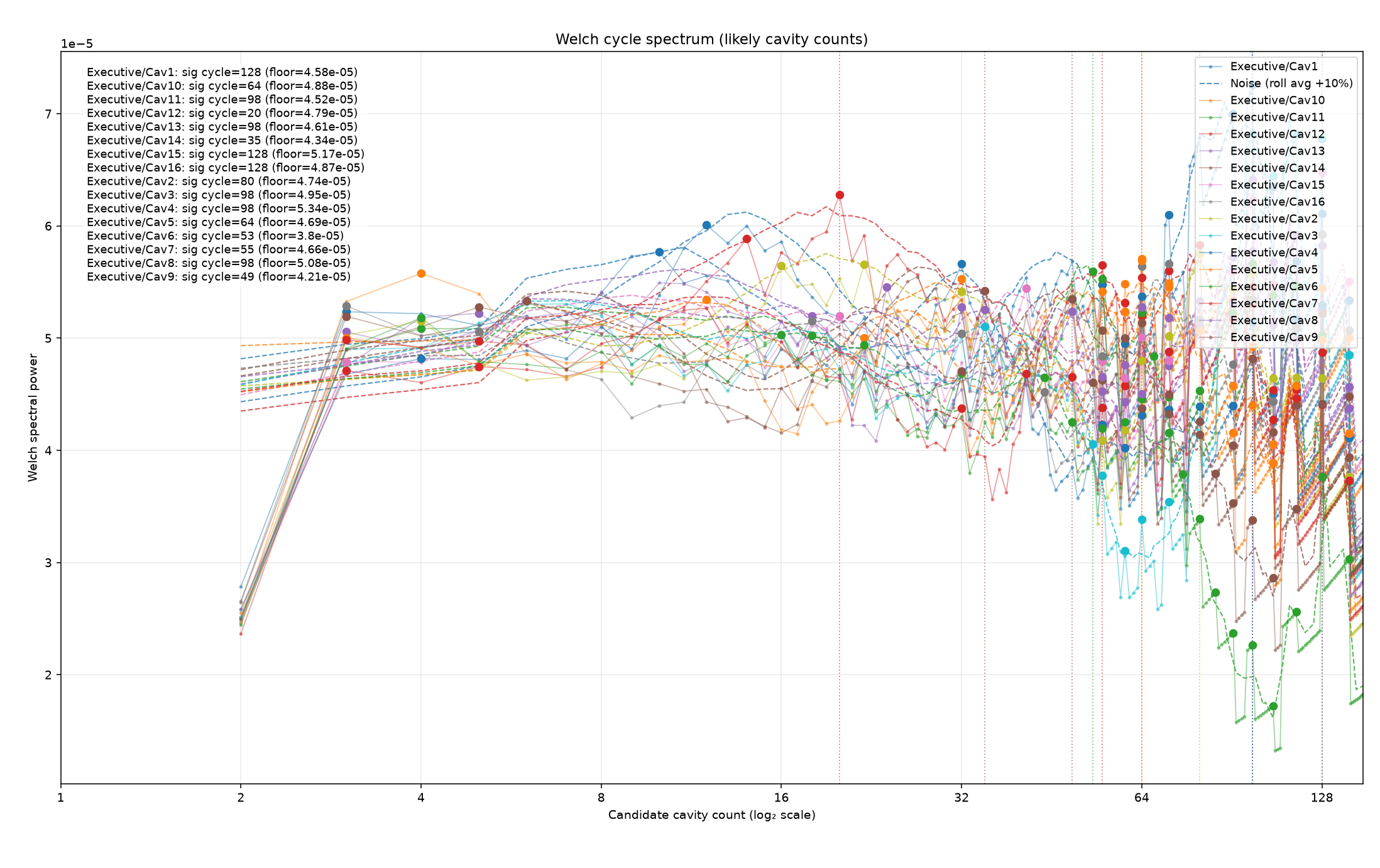
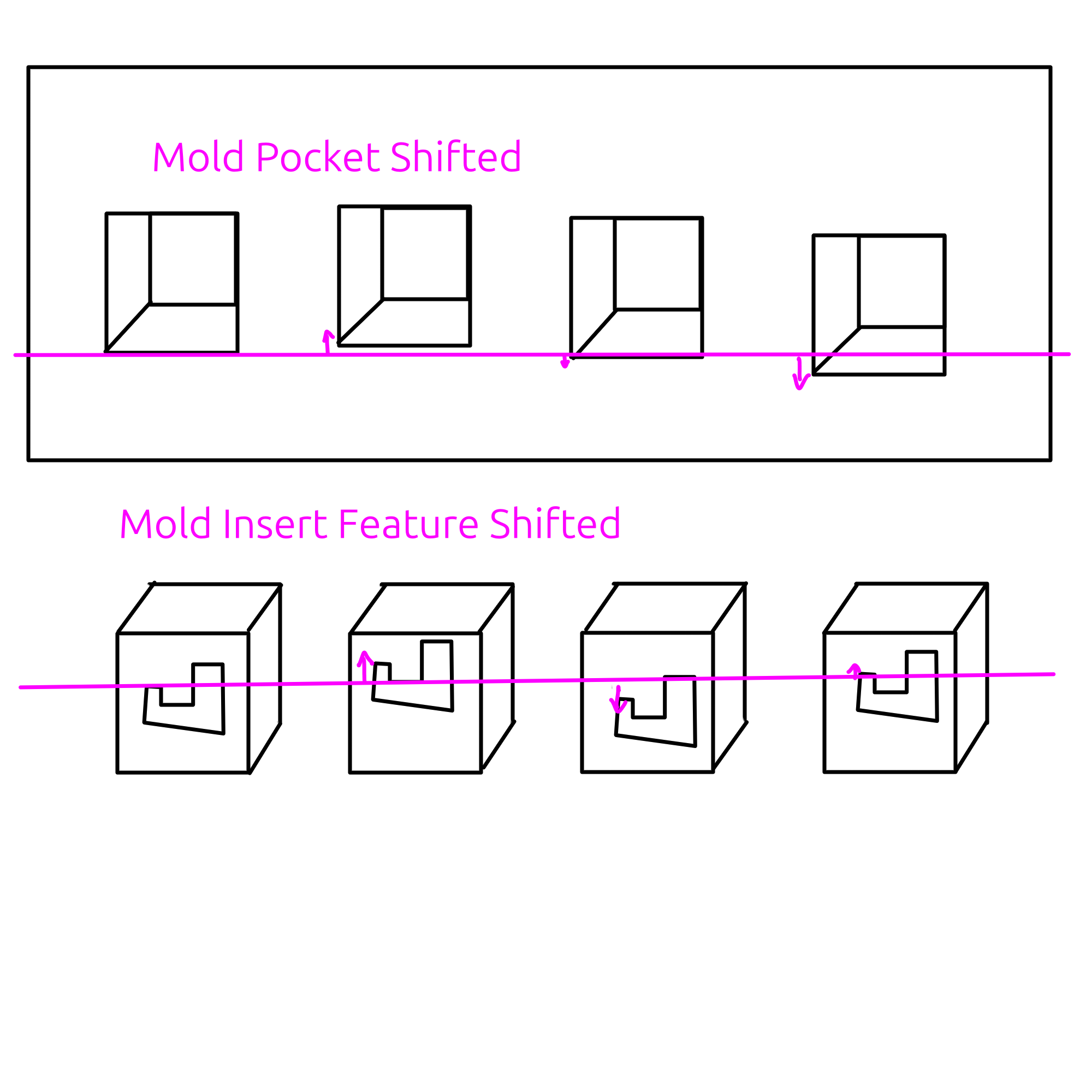
I work with a lot of stamped and overmolded components. For stamped components it is normally fast enough that there is only one cavity. But for molding operations, to keep up with other processes, the mold runs multiple cavities normally 8 or 16 or some exponential of 2.
Anyway here is the setup:
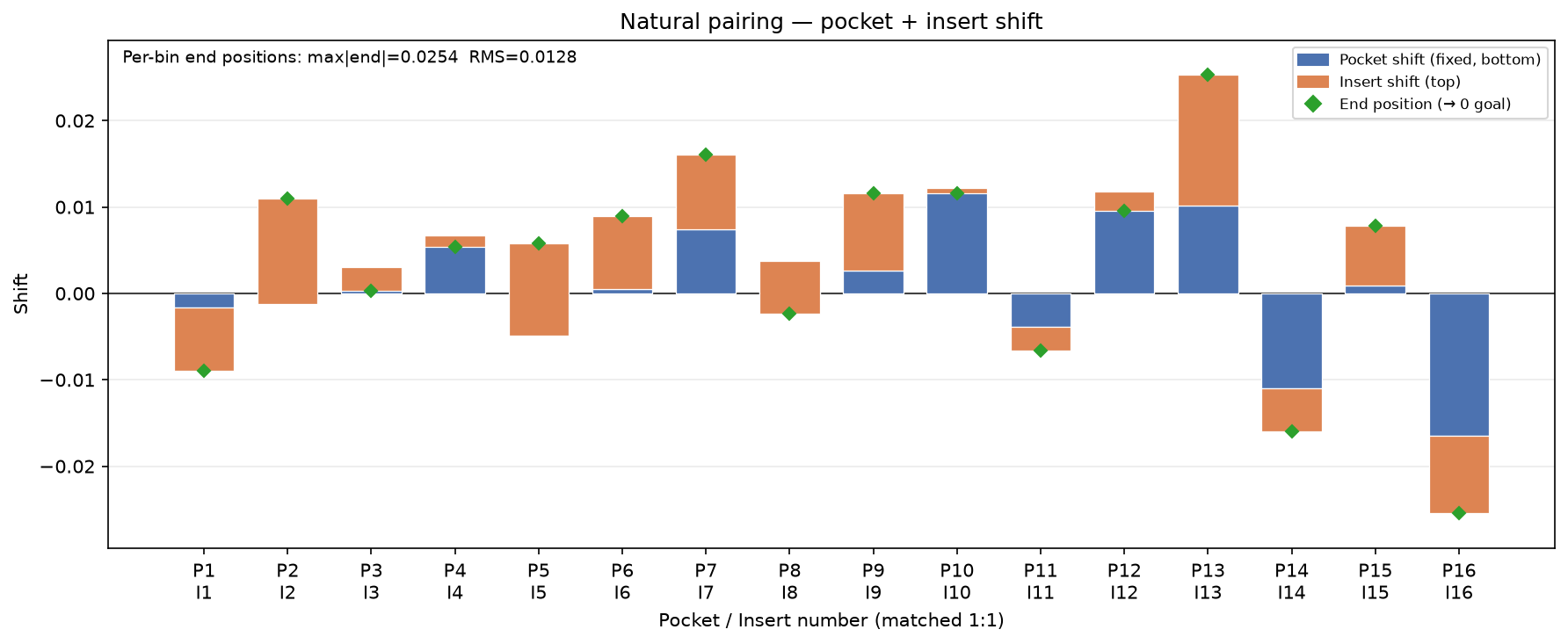
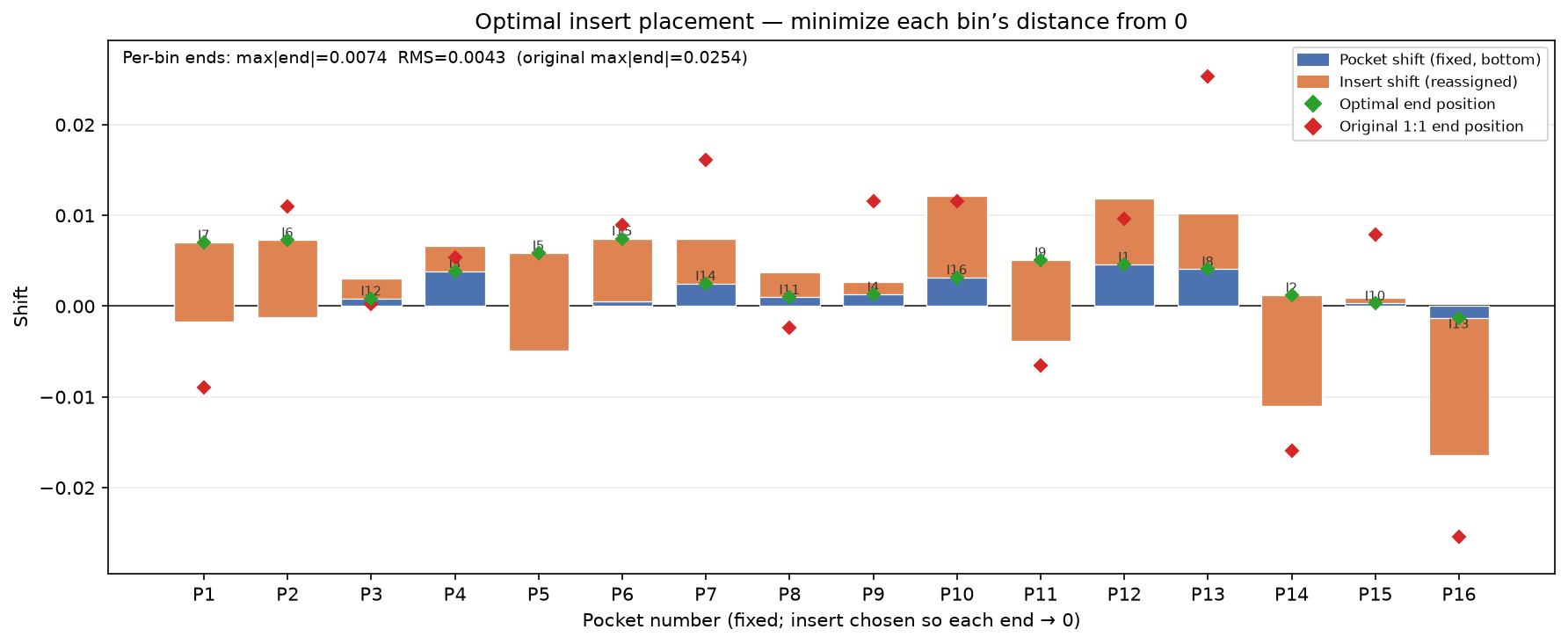
I am given this CSV data, I have a few critical features I need to bring into tighter control:
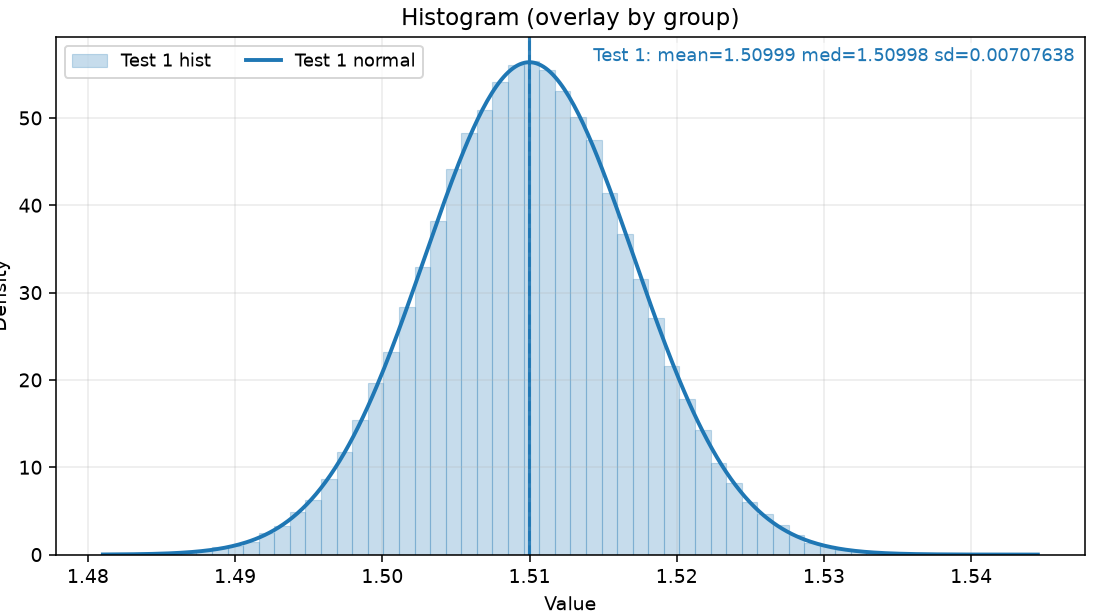
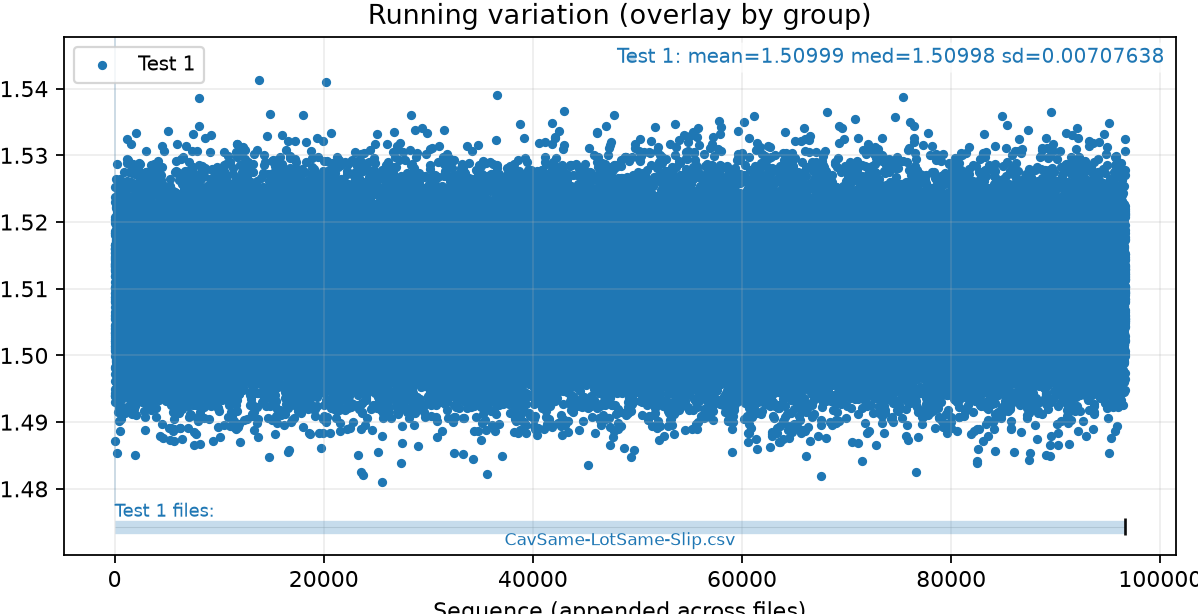
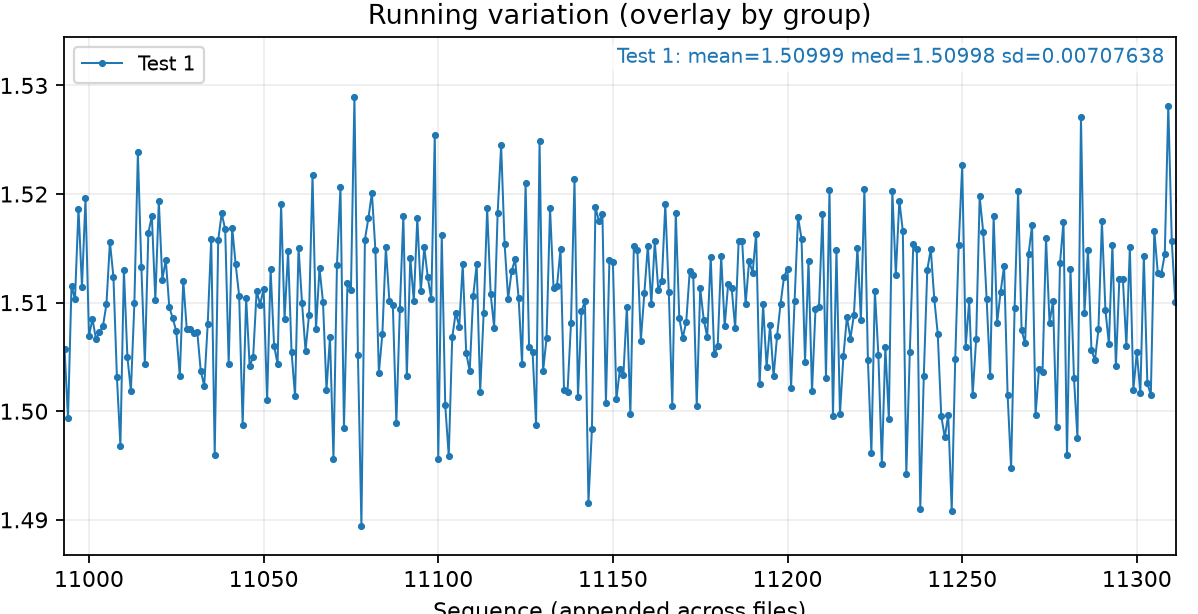
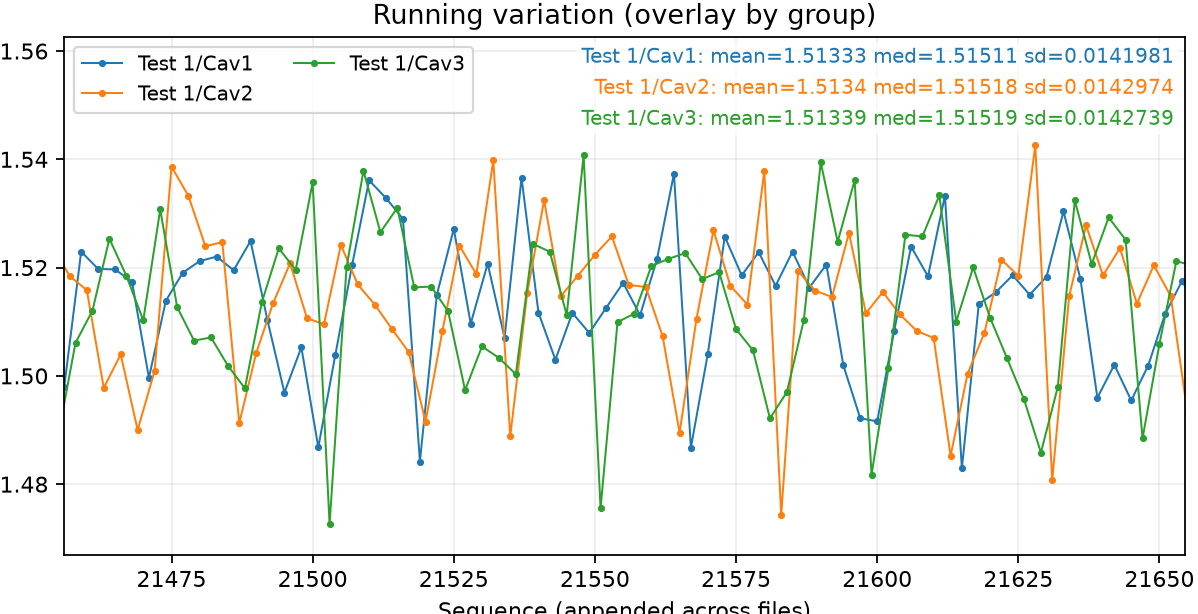
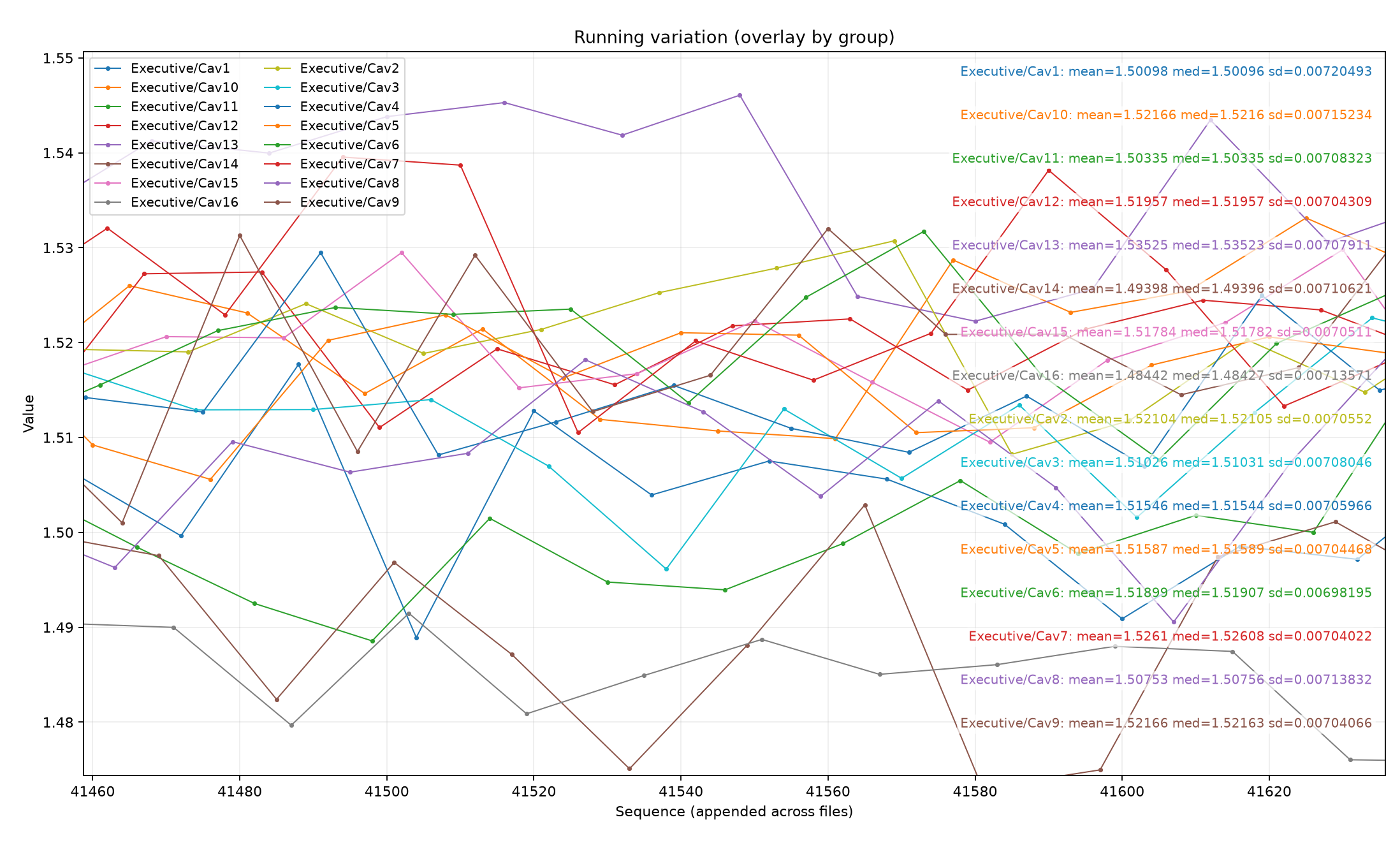
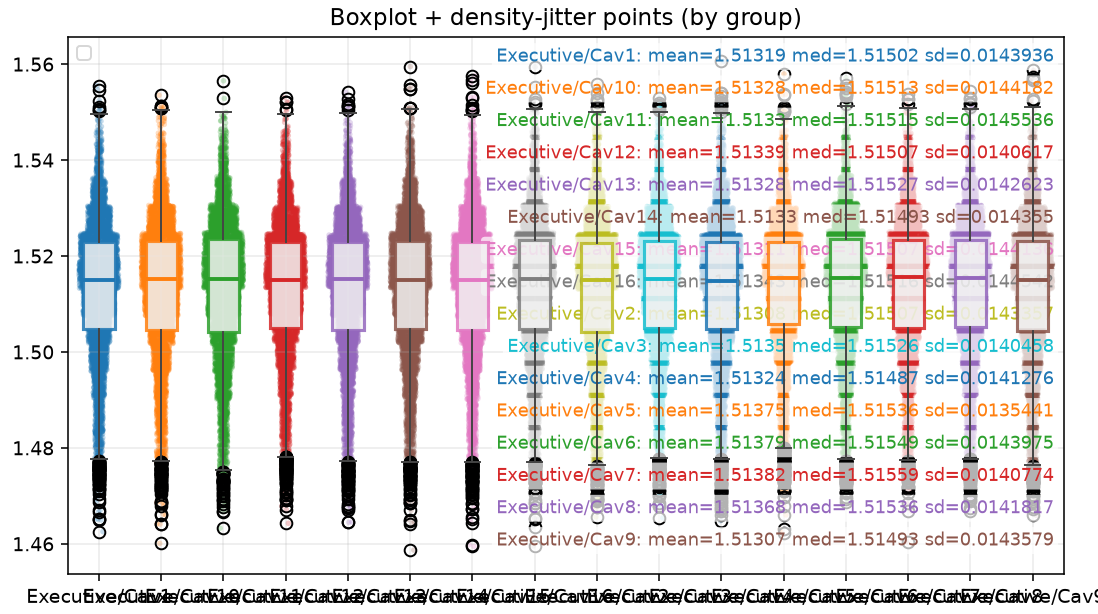
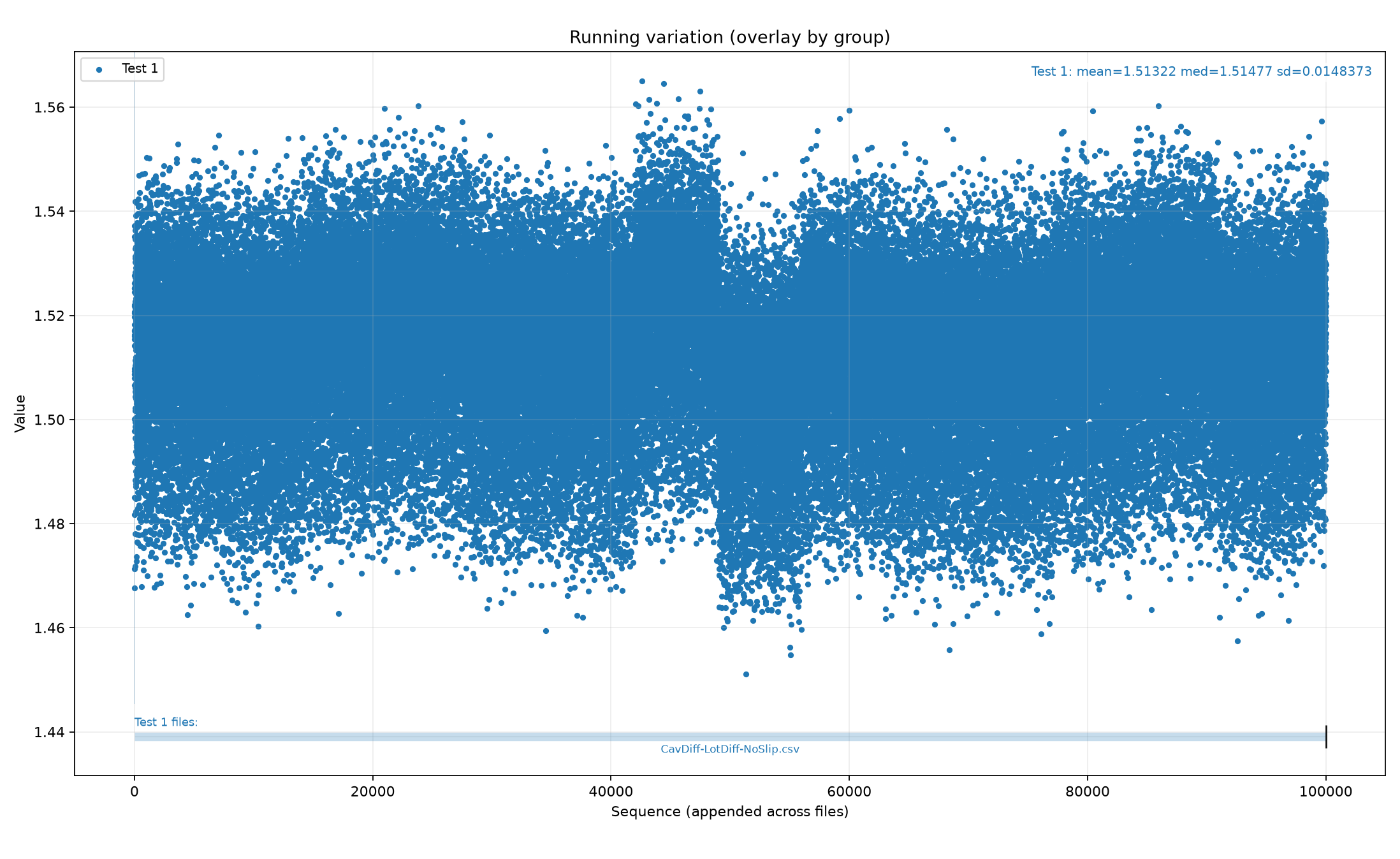
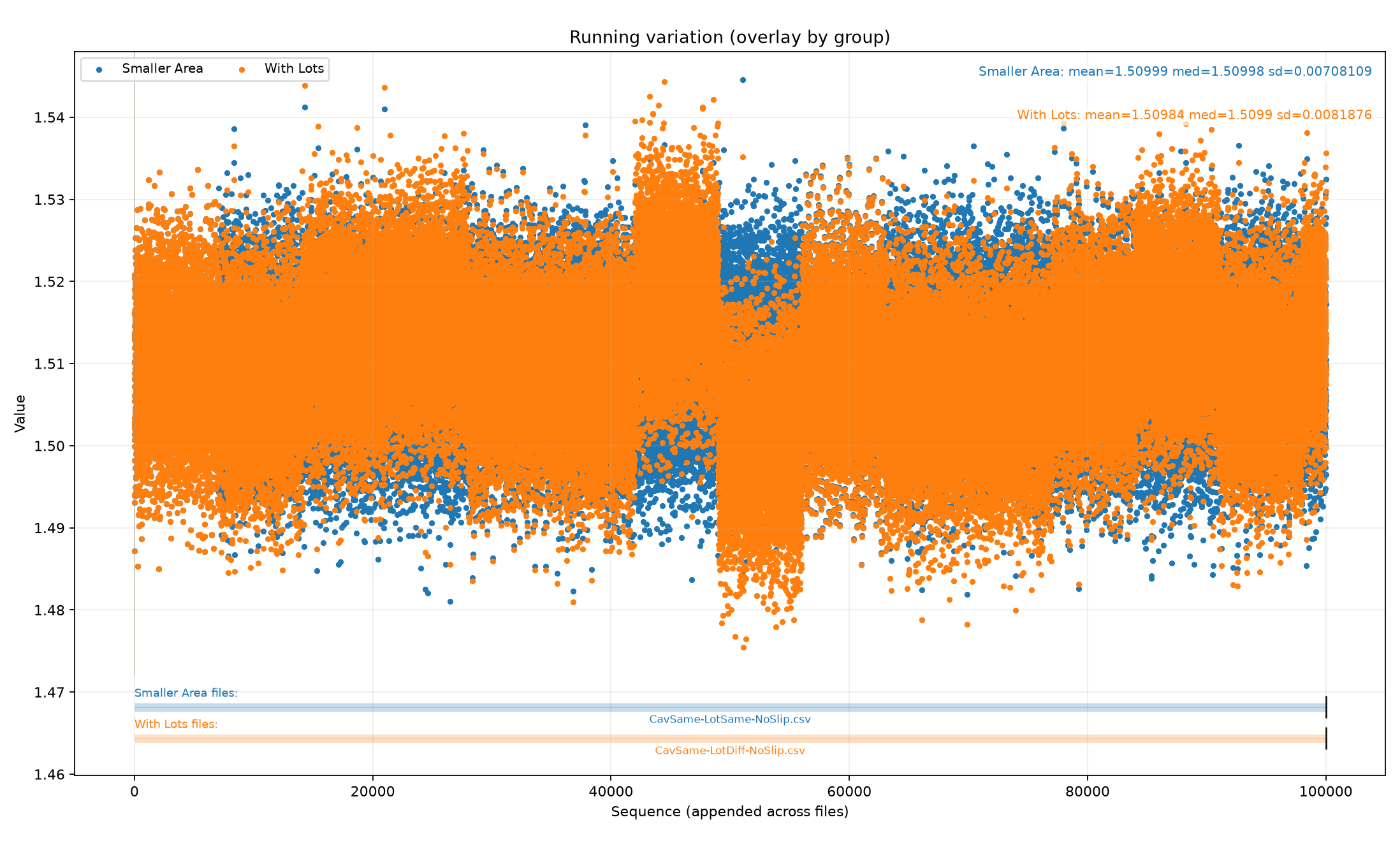
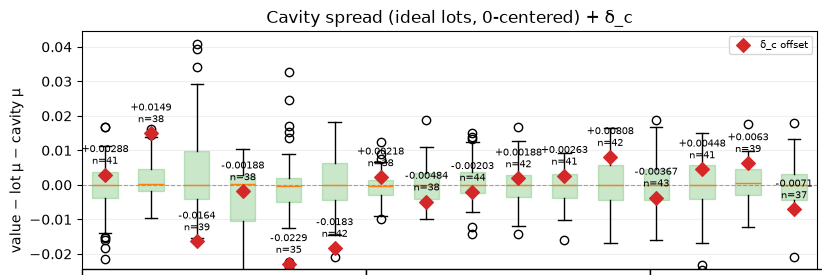
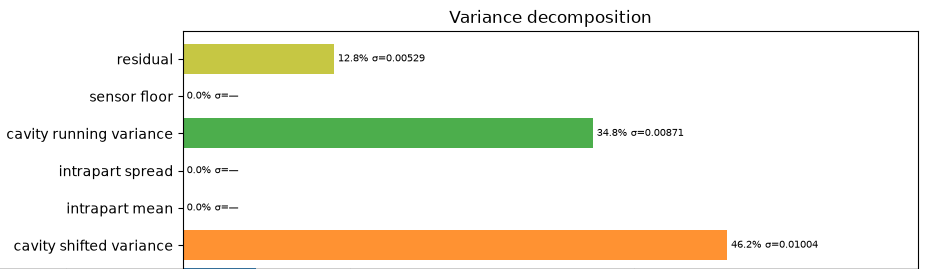
Loading code snippet...First off I just created script to select the measurements and then iterate through and show the normal statistics: median value, standard distribution, and running chart to see how measures change over time.
So here's what that looks like: